今スウェーデン王立工科大という,国内最強の理系大学でサマースクールを受けています.
"Introduction to High-Performance Computing"
というテーマでコードの最適化や並列化についてお勉強中.
さて,現在明日締め切りのプログラミングコンテストに向けてコードを作成中.
NxNの行列の積計算をするプログラムを高速化せよとのこと.プログラム自体は非常~~~に単純なのですが,この最適化を考えると実に奥が深い.
何も考えずに書くとこうでしょう.
2次元配列にしてないから分かりにくいけど,良くある記述ミス.キャッシュヒット率が低下し,実はこれは良くない.
キャッシュヒットを考慮すると,
ええ,i とj ひっくり返しただけです.これだけでメモリアクセスのオーバーヘッドが大幅に削減して相当早くなります.
お次はVectorize. キャッシュヒットと条件分岐判定回数の低減,SIMD命令セットの利用を意識すると,
こいつはさらに速い.前述MulMatの3倍速くなった.4倍にならないのはメモリオーバーヘッドのせいでしょう.あと,resultはあらかじめ初期化しておく必要がある.あと,この時点でハードコーディングになるので,4の倍数の行列同士の計算しか出来なくなってます.
さてさて,お次は更なる効率化.ブロッキングです.キャッシュに残っているデータが必要となる要素の計算を優先し,断片的な解から順に加算していく.ブロッキングのサイズが適切であれば,同じデータをメモリから繰り返し呼び出す回数が少なくなります.条件分岐判定の回数は増えますが,メモリオーバーヘッドに比べればカスみたいなものなので,超速くなります.
今度はMulMat2とMulMat3を合体させましょう.
さぁ,無駄なアドレスの計算も無くしましょう.先頭アドレスをストアして自分でアドレスを指定.これでさらに早くなります.
さーさー,お待ちかね(?)の並列化です.めんどいのでOpenMPの2行でさくっと.Visual Sutudio なら2008で動作確認済み.プロジェクトのプロパティ-言語でOpenMPを有効にして,をインクルード.詳細はググってみてください.
読みづらいことこの上ない.
ちなみにBLOCKのサイズはプロセッサによって変わります.僕はめんどいので適当に32にしたら結構速くなったので,これでいいや,てな感じです.
ついでに,一番最初の処理にOpenMpによる並列化処理を施したものも追加.
いよいよ測定結果です.以下の通り.
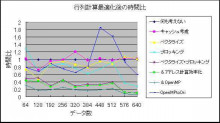
ありゃ~キャッシュ考慮とか単純OpenMP実装あたりが思い通りの結果じゃない!!!
でもとりあえずベクタライズ×ブロッキング×アドレス計算最適化×OpenMPが最強で良かった.
てなわけで学校のLinuxでまわしても動かないorz
もうめんどいから出すのやめたwこんなプログラムで勝てるわけないし,てかハードコーディング禁止だしw
あとサマースクールも2日ですね.終わるとなると寂しいものです.
"Introduction to High-Performance Computing"
というテーマでコードの最適化や並列化についてお勉強中.
さて,現在明日締め切りのプログラミングコンテストに向けてコードを作成中.
NxNの行列の積計算をするプログラムを高速化せよとのこと.プログラム自体は非常~~~に単純なのですが,この最適化を考えると実に奥が深い.
何も考えずに書くとこうでしょう.
void MulMat0(double result[],
const double matA[], const double matB[], const int size)
{
double sum;
for(int j=0; j < size; j++)
for(int i=0; i < size; i++) {
sum=0;
for(int k=0; k < size; k++)
sum += matA[i*size+k]*matB[j+k*size];
result[i*size+j] = sum;
}
}
|
2次元配列にしてないから分かりにくいけど,良くある記述ミス.キャッシュヒット率が低下し,実はこれは良くない.
キャッシュヒットを考慮すると,
void MulMat1(double result[],
const double matA[], const double matB[], const int size)
{
double sum;
for(int i=0; i < size; i++)
for(int j=0; j < size; j++) {
sum=0;
for(int k=0; k < size; k++)
sum += matA[i*size+k]*matB[j+k*size];
result[i*size+j] = sum;
}
}
|
ええ,i とj ひっくり返しただけです.これだけでメモリアクセスのオーバーヘッドが大幅に削減して相当早くなります.
お次はVectorize. キャッシュヒットと条件分岐判定回数の低減,SIMD命令セットの利用を意識すると,
void MulMat2(double result[],
const double matA[], const double matB[], const int size)
{
double sum[4], temp;
for(int k=0; k < size; k++) {
for(int i=0; i < size; i+=4) {
sum[0] = matA[ i*size+k];
sum[1] = matA[(i+1)*size+k];
sum[2] = matA[(i+2)*size+k];
sum[3] = matA[(i+3)*size+k];
for(int j=0; j < size; j++) {
temp = matB[k*size+j];
result[ i*size+j] += sum[0]*temp;
result[(i+1)*size+j] += sum[1]*temp;
result[(i+2)*size+j] += sum[2]*temp;
result[(i+3)*size+j] += sum[3]*temp;
}
}
}
}
|
こいつはさらに速い.前述MulMatの3倍速くなった.4倍にならないのはメモリオーバーヘッドのせいでしょう.あと,resultはあらかじめ初期化しておく必要がある.あと,この時点でハードコーディングになるので,4の倍数の行列同士の計算しか出来なくなってます.
さてさて,お次は更なる効率化.ブロッキングです.キャッシュに残っているデータが必要となる要素の計算を優先し,断片的な解から順に加算していく.ブロッキングのサイズが適切であれば,同じデータをメモリから繰り返し呼び出す回数が少なくなります.条件分岐判定の回数は増えますが,メモリオーバーヘッドに比べればカスみたいなものなので,超速くなります.
void MulMat3(double result[],
const double matA[], const double matB[], const int size)
{
double partSum;
static int block = 4; // depends on a system
for(int i=0; i < size; i++) {
for(int j=0; j < size; j++) {
partSum = 0;
for(int k=0; k < block; k++) {
partSum += matA[i*size+k]*matB[k*size+j];
}
result[i*size+j] += partSum;
}
}
}
|
今度はMulMat2とMulMat3を合体させましょう.
void MulMat5(double result[],
const double matA[], const double matB[], const int size)
{
double temp, partSum[4];
for(int i0=0; i0 < size; i0+=BLOCK) {
for(int j0=0; j0 < size; j0+=BLOCK) {
for(int k0=0; k0 < size; k0+=BLOCK) {
for(int i=i0; i < i0+BLOCK; i++) {
for(int j=j0; j < j0+BLOCK; j+=4) {
partSum[0]=0;
partSum[1]=0;
partSum[2]=0;
partSum[3]=0;
for(int k=k0; k < k0+BLOCK; k++) {
temp = matA[i*size+k];
partSum[0] += temp*matB[k*size+j ];
partSum[1] += temp*matB[k*size+j+1];
partSum[2] += temp*matB[k*size+j+2];
partSum[3] += temp*matB[k*size+j+3];
}
result[i*size+j] += partSum[0];
result[i*size+j+1] += partSum[1];
result[i*size+j+2] += partSum[2];
result[i*size+j+3] += partSum[3];
}
}
}
}
}
}
|
さぁ,無駄なアドレスの計算も無くしましょう.先頭アドレスをストアして自分でアドレスを指定.これでさらに早くなります.
void MulMat7(double result[],
const double matA[], const double matB[], const int size)
{
double temp, partSum[4], *ptemp;
const double *ptempc;
int k;
for(int i0=0; i0 < size; i0+=BLOCK) {
for(int j0=0; j0 < size; j0+=BLOCK) {
for(int k0=0; k0 < size; k0+=BLOCK) {
for(int i=i0; i < i0+BLOCK; i++) {
for(int j=j0; j < j0+BLOCK; j+=4) {
partSum[0]=0;
*(double *)(partSum+1)=0;
*(double *)(partSum+2)=0;
*(double *)(partSum+3)=0;
ptempc = &matB[k0*size+j];
for(k=k0; k < k0+BLOCK; k++) {
temp = matA[i*size+k];
//ptempc = &matB[k*size+j];
*partSum += temp*(*ptempc);
*(double *)(partSum+1) += temp*(*(double *)(ptempc+1));
*(double *)(partSum+2) += temp*(*(double *)(ptempc+2));
*(double *)(partSum+3) += temp*(*(double *)(ptempc+3));
ptempc = (double *)(ptempc + size);
}
ptemp = &result[i*size+j];
*ptemp += *partSum;
*(double *)(ptemp+1) += *(double *)(partSum+1);
*(double *)(ptemp+2) += *(double *)(partSum+2);
*(double *)(ptemp+3) += *(double *)(partSum+3);
}
}
}
}
}
}
|
さーさー,お待ちかね(?)の並列化です.めんどいのでOpenMPの2行でさくっと.Visual Sutudio なら2008で動作確認済み.プロジェクトのプロパティ-言語でOpenMPを有効にして,
void MulMat9(double result[],
const double matA[], const double matB[], const int size)
{
double temp, partSum[4], *ptemp;
const double *ptempc;
int i, j, k;
#pragma omp parallel shared(matA, matB, result)
for(int j0=0; j0 < size; j0+=BLOCK) {
for(int k0=0; k0 < size; k0+=BLOCK) {
#pragma omp for private(i, j, k, partSum, temp, ptemp, ptempc)
for(i=0; i < size; i++) {
for(j=j0; j < j0+BLOCK; j+=4) {
partSum[0]=0;
*(double *)(partSum+1)=0;
*(double *)(partSum+2)=0;
*(double *)(partSum+3)=0;
ptempc = &matB[k0*size+j];
for(k=k0; k < k0+BLOCK; k++) {
temp = matA[i*size+k];
//ptempc = &matB[k*size+j];
*partSum += temp*(*ptempc);
*(double *)(partSum+1) += temp*(*(double *)(ptempc+1));
*(double *)(partSum+2) += temp*(*(double *)(ptempc+2));
*(double *)(partSum+3) += temp*(*(double *)(ptempc+3));
ptempc = (double *)(ptempc + size);
}
ptemp = &result[i*size+j];
*ptemp += *partSum;
*(double *)(ptemp+1) += *(double *)(partSum+1);
*(double *)(ptemp+2) += *(double *)(partSum+2);
*(double *)(ptemp+3) += *(double *)(partSum+3);
}
}
}
}
}
|
読みづらいことこの上ない.
ちなみにBLOCKのサイズはプロセッサによって変わります.僕はめんどいので適当に32にしたら結構速くなったので,これでいいや,てな感じです.
ついでに,一番最初の処理にOpenMpによる並列化処理を施したものも追加.
void MulMatP(double result[],
const double matA[], const double matB[], const int size)
{
double sum;
int i, j, k;
#pragma omp parallel for private(i, j, k, sum) shared(matA, matB, result)
for(i=0; i < size; i++)
for(j=0; j
|
いよいよ測定結果です.以下の通り.
ありゃ~キャッシュ考慮とか単純OpenMP実装あたりが思い通りの結果じゃない!!!
でもとりあえずベクタライズ×ブロッキング×アドレス計算最適化×OpenMPが最強で良かった.
てなわけで学校のLinuxでまわしても動かないorz
もうめんどいから出すのやめたwこんなプログラムで勝てるわけないし,てかハードコーディング禁止だしw
あとサマースクールも2日ですね.終わるとなると寂しいものです.
0 件のコメント:
コメントを投稿